Question
Given two sentences words1, words2 (each represented as an array of strings), and a list of similar word pairs pairs, determine if two sentences are similar.
For example, words1 = ["great", "acting", "skills"] and words2 = ["fine", "drama", "talent"] are similar, if the similar word pairs are pairs = [["great", "good"], ["fine", "good"], ["acting","drama"], ["skills","talent"]].
Note that the similarity relation is transitive. For example, if "great" and "good" are similar, and "fine" and "good" are similar, then "great" and "fine" are similar.
Similarity is also symmetric. For example, "great" and "fine" being similar is the same as "fine" and "great" being similar.
Also, a word is always similar with itself. For example, the sentences words1 = ["great"], words2 = ["great"], pairs = [] are similar, even though there are no specified similar word pairs.
Finally, sentences can only be similar if they have the same number of words. So a sentence like words1 = ["great"] can never be similar to words2 = ["doubleplus","good"].
Note:
- The length of
words1andwords2will not exceed1000. - The length of
pairswill not exceed2000. - The length of each
pairs[i]will be2. - The length of each
words[i]andpairs[i][j]will be in the range[1, 20].
Difficulty:Medium
Category:
Analyze
这道题目的同义单词之间是具有传递性的,我们首先要做的就是建立这个连通图(同义词)的数据结构,对于每个结点来说,我们要记录所有和其相连的结点,所以我们建立每个结点和其所有相连结点集合之间的映射,比如对于这三个相似对(a, b), (b, c),和(c, d),我们让a,b,c到一个集合里面去.(Union Find)
Solution
Cite: 花花酱 LeetCode 737. Sentence Similarity II
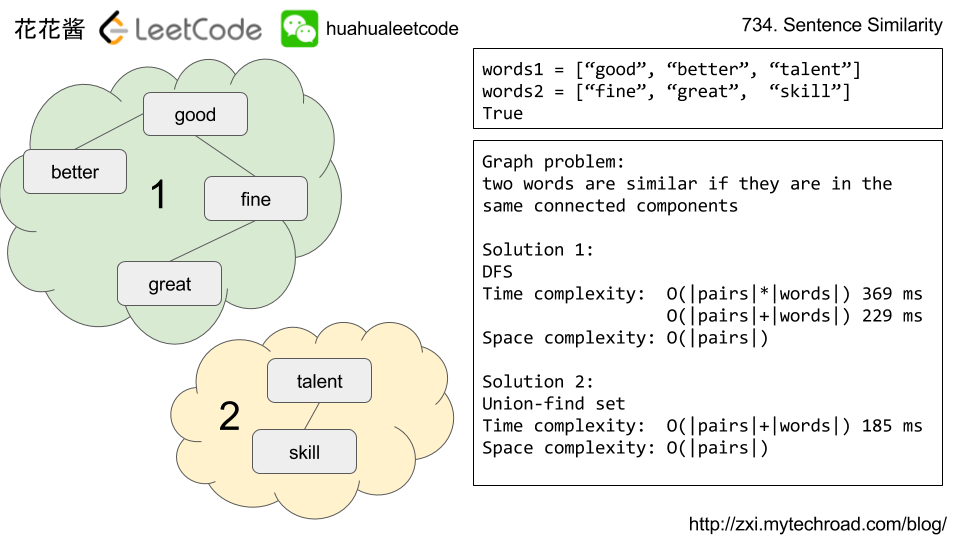
Solution 1: Union Find
Time complexity: O(|Pairs| + |words1|), Space complexity: O(|Pairs|)
class UnionFindSet {
public:
bool Union(const string& word1, const string& word2) {
const string& p1 = Find(word1, true);
const string& p2 = Find(word2, true);
if (p1 == p2) return false;
parents_[p1] = p2;
return true;
}
const string& Find(const string& word, bool create = false) {
if (!parents_.count(word)) {
if (!create) return word;
return parents_[word] = word;
}
string w = word;
while (w != parents_[w]) {
parents_[w] = parents_[parents_[w]];
w = parents_[w];
}
return parents_[w];
}
private:
unordered_map<string, string> parents_;
};
class Solution {
public:
bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<pair<string, string>>& pairs) {
if (words1.size() != words2.size()) return false;
UnionFindSet s;
for (const auto& pair : pairs) s.Union(pair.first, pair.second);
for (int i = 0; i < words1.size(); ++i)
if (s.Find(words1[i]) != s.Find(words2[i])) return false;
return true;
}
};
对上面的方法做一些简单的优化(Optimized),可以得到:
class UnionFindSet {
public:
UnionFindSet(int n) {
parents_ = vector<int>(n + 1, 0);
ranks_ = vector<int>(n + 1, 0);
for (int i = 0; i < parents_.size(); ++i) parents_[i] = i;
}
bool Union(int u, int v) {
int pu = Find(u);
int pv = Find(v);
if (pu == pv) return false;
if (ranks_[pu] > ranks_[pv]) {
parents_[pv] = pu;
} else if (ranks_[pv] > ranks_[pu]) {
parents_[pu] = pv;
} else {
parents_[pu] = pv;
++ranks_[pv];
}
return true;
}
int Find(int id) {
if (id != parents_[id]) parents_[id] = Find(parents_[id]);
return parents_[id];
}
private:
vector<int> parents_;
vector<int> ranks_;
};
class Solution {
public:
bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<pair<string, string>>& pairs) {
if (words1.size() != words2.size()) return false;
UnionFindSet s(pairs.size() * 2);
unordered_map<string, int> indies; // word to index
for (const auto& pair : pairs) {
int u = getIndex(pair.first, indies, true);
int v = getIndex(pair.second, indies, true);
s.Union(u, v);
}
for (int i = 0; i < words1.size(); ++i) {
if (words1[i] == words2[i]) continue;
int u = getIndex(words1[i], indies);
int v = getIndex(words2[i], indies);
if (u < 0 || v < 0) return false;
if (s.Find(u) != s.Find(v)) return false;
}
return true;
}
private:
int getIndex(const string& word, unordered_map<string, int>& indies, bool create = false) {
auto it = indies.find(word);
if (it == indies.end()) {
if (!create) return INT_MIN;
int index = indies.size();
indies.emplace(word, index);
return index;
}
return it->second;
}
};
cite: Sentence Similarity II 句子相似度之二
另外一种写法,简化后。这种解法的核心是一个getRoot函数,如果两个元素属于同一个群组的话,调用getRoot函数会返回相同的值。主要分为两部,第一步是建立群组关系,suppose开始时每一个元素都是独立的个体,各自属于不同的群组。然后对于每一个给定的关系对,我们对两个单词分别调用getRoot函数,找到二者的祖先结点,如果从未建立过联系的话,那么二者的祖先结点时不同的,此时就要建立二者的关系。等所有的关系都建立好了以后,第二步就是验证两个任意的元素是否属于同一个群组,就只需要比较二者的祖先结点都否相同啦。是不是有点深度学习的赶脚,先建立模型training,然后再test。哈哈,博主乱扯的,二者并没有什么联系。我们保存群组关系的数据结构,有时用数组,有时用哈希map,看输入的数据类型吧,如果输入元素的整型数的话,用root数组就可以了,如果是像本题这种的字符串的话,需要用哈希表来建立映射,建立每一个结点和其祖先结点的映射。注意这里的祖先结点不一定是最终祖先结点,而最终祖先结点的映射一定是最重祖先结点,所以我们的getRoot函数的设计思路就是要找到最终祖先结点,那么就是当结点和其映射结点相同时返回,否则继续循环,可以递归写,也可以迭代写,这无所谓。注意这里第一行判空是相当于初始化,这个操作可以在外面写,就是要让初始时每个元素属于不同的群组
class Solution {
public:
bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<pair<string, string>> pairs) {
if (words1.size() != words2.size()) return false;
unordered_map<string, string> m;
for (auto pair : pairs) {
string x = getRoot(pair.first, m), y = getRoot(pair.second, m);
if (x != y) m[x] = y;
}
for (int i = 0; i < words1.size(); ++i) {
if (getRoot(words1[i], m) != getRoot(words2[i], m)) return false;
}
return true;
}
string getRoot(string word, unordered_map<string, string>& m) {
if (!m.count(word)) m[word] = word;
return word == m[word] ? word : getRoot(m[word], m);
}
};
Solution 2: Recursion + DFS
Cite: Sentence Similarity II 句子相似度之二
class Solution {
public:
bool areSentencesSimilarTwo(vector<string>& words1, vector<string>& words2, vector<pair<string, string>>& pairs) {
if (words1.size() != words2.size()) return false;
g_.clear();
for (const auto& p : pairs) {
g_[p.first].insert(p.second);
g_[p.second].insert(p.first);
}
unordered_set<string> visited;
for (int i = 0; i < words1.size(); ++i) {
visited.clear();
if (!dfs(words1[i], words2[i], visited)) return false;
}
return true;
}
private:
bool dfs(const string& src, const string& dst, unordered_set<string>& visited) {
if (src == dst) return true;
visited.insert(src);
for (const auto& next : g_[src]) {
if (visited.count(next)) continue;
if (dfs(next, dst, visited)) return true;
}
return false;
}
unordered_map<string, unordered_set<string>> g_;
};